⇛ CPU Utilization
The problem occurs when the processor is so overloaded that it cannot respond to requests for time. In other words, the central processing unit (CPU) is overloaded and unable to accomplish tasks in a timely manner. A CPU bottleneck manifests as two things: a processor running at over 80 percent capacity for a prolonged period, and an overly long processor queue. The main reasons for CPU utilization bottlenecks are insufficient system memory and constant interruptions from input/output devices. In order to resolve these issues, you need to increase CPU power, add more random access memory (RAM), and improve software coding efficiency.
Due to the growing complexity of websites and apps-with more JavaScript, more images, and layers of complexity that simply weren’t considered in the mid-2000s-it has become increasingly important to pay attention to browser performance on mobile devices, especially those that don’t have a lot of memory or a powerful CPU. Try running your app on devices with varying CPU capabilities and see how it runs using Chrome DevTools to throttle the CPU. Make sure not to go easy on the CPU. By pushing it to its limits, you’ll expose its weaknesses. Additionally, these stress tests will help detect performance hiccups.
⇛ Software Limitations
Performance dips caused by bottlenecks can sometimes be caused by software. Programs can sometimes be built to handle only a finite number of tasks at once, so even when additional resources are available, the program won’t use any of them.
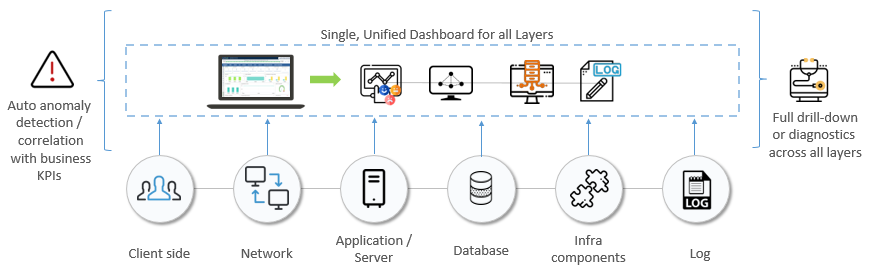
In most cases, application problems arise from transactions that overload the database or system resources, such as static content, authentication, connection pools, etc. in an inefficient manner. There are many instances where application environments, such as web servers, are configured with default settings that do not respond well to peak load traffic.
⇛ Disk Usage
Long-term storage, which includes HDDs and SSDs, is usually the slowest component inside a computer or server and is often an unavoidable bottleneck. It can be difficult to troubleshoot this bottleneck because even the fastest long-term storage solutions have physical speed limits. On a physical level, address insufficient bandwidth by switching to faster storage devices and expanding RAID (a data storage virtualization technology) configurations.
⇛ Memory Utilization
There is a memory bottleneck when there is not enough or fast enough RAM in the system. This limits the speed at which the RAM can serve information to the CPU, which slows down overall application performance. When the system has insufficient memory, the computer will start offloading storage to a much slower hard disk drive (HDD) or solid-state drive (SSD). The device will experience a slowdown and low CPU usage if the RAM is unable to serve data fast enough to the CPU.
Typically, the issue is resolved by installing more memory or faster RAM. When RAM is too slow, it must be replaced, whereas capacity bottlenecks can be resolved simply by adding more memory. Often, the problem arises from a programming error known as a “memory leak,” which occurs when a program does not release memory to the system after it has been used. An update to the program is required to fix this issue.
⇛ Server Performance
If you only concentrate on the front end and neglect the back end, you could be setting yourself up for failure. Bottlenecks and performance glitches can also occur on the server, which must be closely monitoring and detecting anomalies with application performance monitoring (APM) software, you can prevent major problems in the future.
When it comes to APM, there is a substantial divide between front-end and back-end developers. Companies with JavaScript-heavy front ends are less likely to use APM, while those with more traditional backends, or those with complex front ends, are more likely to use APM. Due to this, both camps deserve a monitoring solution that integrates what users see on the front end with the backend processing, which can often be achieved through the concept of a Business Transaction.