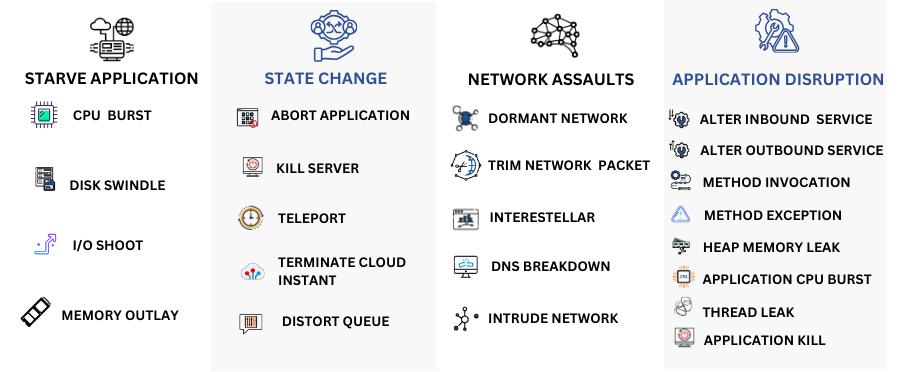
By supporting a wide array of platforms, including Linux, AWS, Azure, Google Cloud, Docker, Kubernetes, Windows, and Pivotal Cloud Foundry, NetHavoc ensure comprehensive applicability. Furthermore, with the addition of IBM Cloud Foundry to its arsenal, NetHavoc enhances its compatibility with diverse IT environments, making it an essential tool for robust and effective reliability testing.
❖ Building Customer Trust
By addressing potential failures before they impact customer experience, NetHavoc helps you keep your customers at the center of your innovation efforts. Proactively improving system reliability builds customer trust and confidence.
❖ Reducing MTTD & MTTR
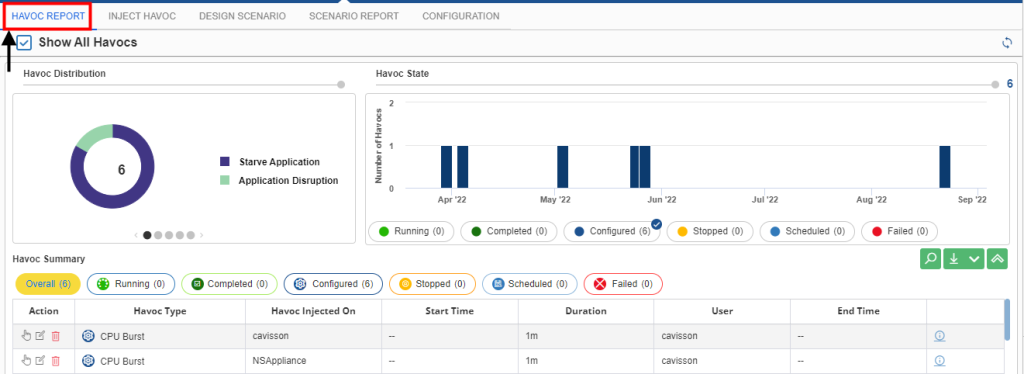
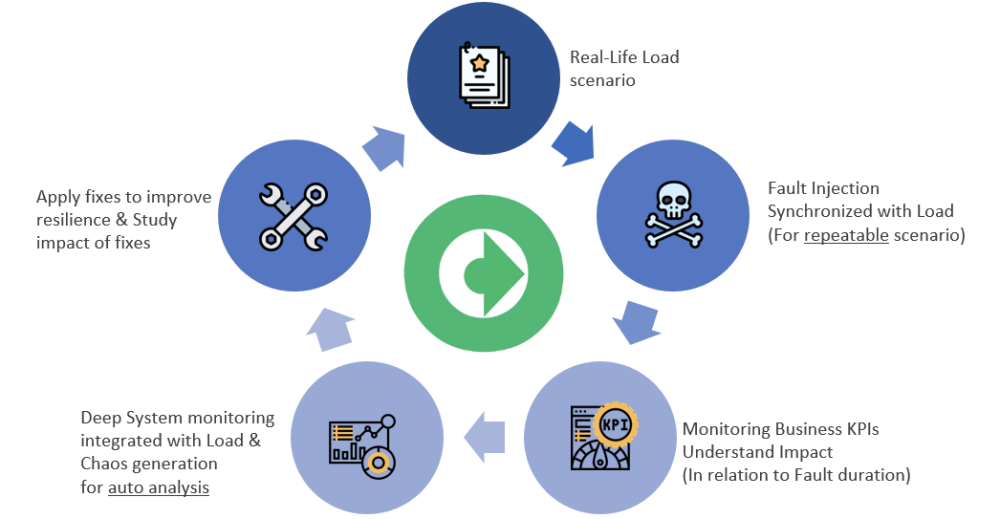
NetHavoc reduces Mean Time to Detect (MTTD) and Mean Time to Repair (MTTR) by seamlessly integrating performance testing and observability, enabling IT teams to identify and resolve issues swiftly. This integration allows for comprehensive resilience testing by combining performance and chaos engineering, simulating high traffic and failure scenarios to pinpoint vulnerabilities. Through deep-dive diagnostics and continuous monitoring of complex applications, NetHavoc provides detailed insights into performance issues, helping teams protect resources and maintain operational efficiency. This holistic approach ensures applications are robust, reliable, and prepared for high-stress conditions.
❖ Reducing Cost of Downtime
Downtime can be costly. NetHavoc allows you to be proactive in testing your system’s weaknesses and addressing them before they result in significant financial implications and public outages .
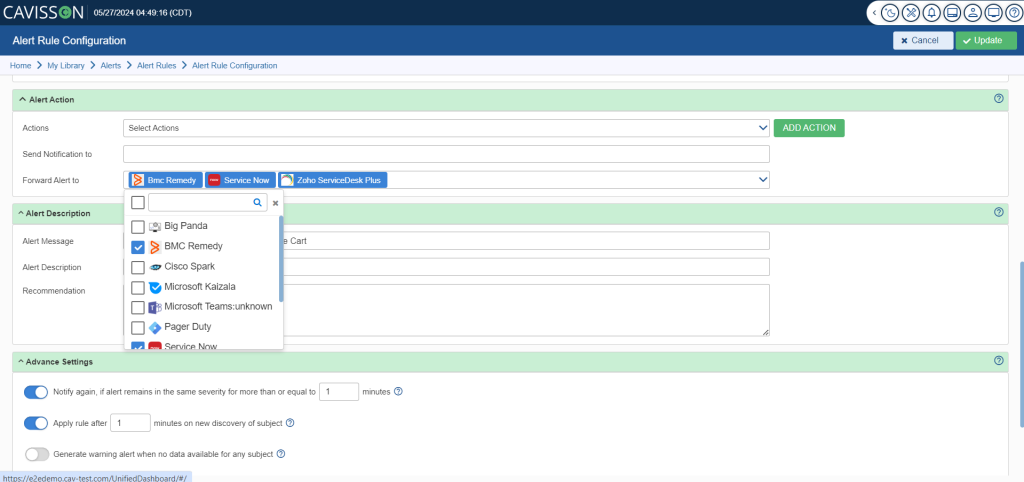
❖ Advanced Alerting
Cavisson Systems’ platform features advanced alerting capabilities, enabling users to generate alerts during or after chaos experiments. These alerts can be sent to various IT Service Management (ITSM) and messaging platforms, including BigPanda, BMC Remedy, Cisco Spark, Microsoft Kaizala, PagerDuty, ServiceNow, Slack, Zoho ServiceDesk Plus, and other Cavisson products.